搜索引擎的基础是有大量网页的信息数据库,这是决定搜索引擎整体质量的一个重要指标。如果搜索引擎的网页信息量小,那么供用户选择的搜索结果就更少;而大量的网页信息能更好的满足用户的搜索需求。
要获得大量网页信息的数据库,搜索引擎就必须收集网络资源,这项工作是通过搜索引擎的网络漫游器(Crawler),在互联网中各个网页爬行并抓取信息。这是一种爬行并收集信息的程序,通常搜索引擎称为蜘蛛(Spider)或者机器人(Bot)。工作原理如图 2.0
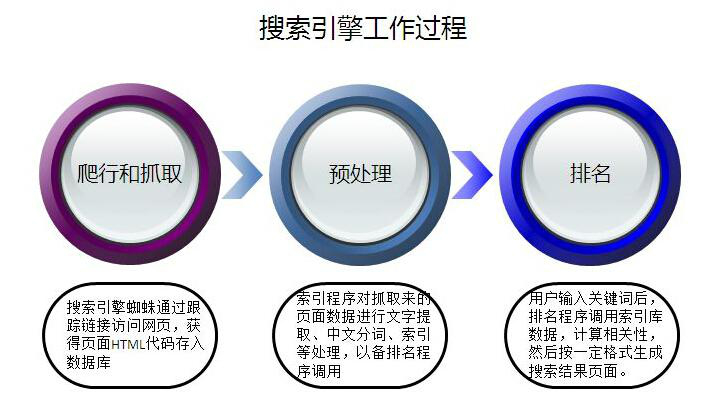
图 2.0

搜索引擎的基础是有大量网页的信息数据库,这是决定搜索引擎整体质量的一个重要指标。如果搜索引擎的网页信息量小,那么供用户选择的搜索结果就更少;而大量的网页信息能更好的满足用户的搜索需求。
要获得大量网页信息的数据库,搜索引擎就必须收集网络资源,这项工作是通过搜索引擎的网络漫游器(Crawler),在互联网中各个网页爬行并抓取信息。这是一种爬行并收集信息的程序,通常搜索引擎称为蜘蛛(Spider)或者机器人(Bot)。工作原理如图 2.0
图 2.0
